How can we train and deploy object detection models faster?
We have heard your feedback, and today we are happy to announce support for training object detection models on Cloud TPU, model quantization (model discretization), and adding some new models including RetinaNet and MobileNet. With Cloud TPU, we can train and run machine learning models at an unprecedented speed. You can view announcement posts on the AI ​​blog. In this article, we will guide you to use transfer learning to train a quantitative pet breed detector on Cloud TPU.

The whole process-from training to inference on an Android device-takes 30 minutes, and Google Cloud costs less than $5. When you are finished, you will have an Android application (we are about to launch iOS related tutorials), which can detect the breeds of dogs and cats in real time, and this App does not occupy more than 12Mb of space on the phone. Please note that in addition to training object detection models in Google Cloud, you can also train on your own hardware or Colab.
Note: Colab link https://colab.research.google.com
Development environment setup
First, we will install a series of libraries required for training and deployment of the model and meet some prerequisites. Please note that this process may take longer than training and deploying the model itself. For convenience, you can use a Dockerfile here, which provides the dependencies required to install Tensorflow, and download the necessary data sets and models for this tutorial.
Note: Dockerfile link
https://github.com/tensorflow/models/blob/master/research/object_detection/dockerfiles/android/Dockerfile
If you decide to use Docker, you should read the "Google Cloud Setup" section and then skip to "Uploading dataset to GCS". The Dockerfile will also build and compile the dependencies required for Android for Tensorflow Lite. For more information, please refer to the attached README file.
Set up GoogleCloud
First, create a project in the Google Cloud Console and enable billing for the project. We will use Cloud Machine Learning Engine to run our training tasks on Cloud TPU. ML Engine is Google Cloud's TensorFlow hosting platform, which simplifies the process of training and deploying ML models. To use it, enable the necessary APIs for the project you just created.
Note:
Create a project link in the Google Cloud Console https://console.cloud.google.com/
Enable necessary API links
https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component&_ga=2.43515109.-1978295503.1509743045
Second, we will create a Google Cloud Storage bucket to store the training and test data of the model, as well as model checkpoints. Please note that all commands in this tutorial assume that you are running on an Ubuntu system. Many of the commands in this tutorial come from the Google Cloud gcloud CLI, and we use the Cloud Storage gsutil CLI to interact with the GCS bucket. If you have not installed these, you can install gcloud and gsutil here.
Note:
gcloud link
https://cloud.google.com/sdk/docs/quickstart-debian-ubuntu
gsutil link
https://cloud.google.com/storage/docs/gsutil_install
Run the following command to set the current project as the project you just created, replacing YOUR_PROJECT_NAME with the project name:
1 gcloud config set project YOUR_PROJECT_NAME
Then, we will create a cloud storage bucket using the following command. Note that the bucket name must be globally unique.
1 gsutil mb gs://YOUR_UNIQUE_BUCKET_NAME
This may prompt you to run gcloud auth login first, and then you need to provide the verification code sent to the browser.
Then set two environment variables to simplify the way you use the commands in this tutorial:
1 export PROJECT="YOUR_PROJECT_ID"
2 export YOUR_GCS_BUCKET="YOUR_UNIQUE_BUCKET_NAME"
Next, in order for Cloud TPU to access our project, we need to add a TPU specific service account. First, use the following command to get the name of the service account:
1 curl -H "Authorization: Bearer $(gcloud auth print-access-token)" \
2 https://ml.googleapis.com/v1/projects/${PROJECT}:getConfig
When this command completes, copy the value of tpuServiceAccount (it looks like rviceaccount.com) and save it as an environment variable:
1 export TPU_ACCOUNT=your-service-account
Finally, grant the ml.serviceAgent role to your TPU service account:
1 gcloud projects add-iam-policy-binding $PROJECT \
2 --member serviceAccount:$TPU_ACCOUNT --role roles/ml.serviceAgent
Install Tensorflow
If you don't have TensorFlow installed, please follow the steps here. In order to be able to operate on the device, you need to install TensorFlow from source code using Bazel as described here. Compiling TensorFlow may take a while. If you only want to follow the Cloud TPU training part of this tutorial, you do not need to compile TensorFlow from the source code. You can directly install the released version through tools such as pip and Anaconda.
Note: Step operation link https://
Install TensorFlow object detection
If this is your first time using TensorFlow object detection, we will welcome your first attempt! To install it, follow the instructions here.
Note: Description link
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
Once the object detection is installed, be sure to test whether the installation is successful by running the following command:
1 python object_detection/builders/model_builder_test.py
If the installation is successful, you should see the following output:
1 Ran 18 tests in 0.079s
2
3 OK
Set up the data set
For simplicity, we will use the same pet breed data set from the previous article. The data set includes approximately 7,400 images involving 37 different breeds of cats and dogs. Each image has an associated annotation file, which includes the bounding box coordinates of the specific pet in the image. We cannot directly provide these images and annotations to our model; so we need to convert them into a format that the model can understand. For this, we will use the TFRecord format.
In order to go directly to the training session, we have published the files pet_faces_train.record and pet_faces_val.record, click here to make them public. You can use public TFRecord files, or if you want to generate them yourself, follow the steps here.
Note: public link here
http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz
You can download and unzip the public TFRecord file using the following command:
1 mkdir /tmp/pet_faces_tfrecord/
2 cd /tmp/pet_faces_tfrecord/
3 curl "http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz" | tar xzf-
Please note that these TFRecord files are fragmented, so once you extract them, you will have 10 pet_faces_train.record files and 10 pet_faces_val.record files.
Upload data set to GCS
Once you get the TFRecord files, copy them to the data subdirectory of the GCS bucket:
1 gsutil -m cp -r /tmp/pet_faces_tfrecord/pet_faces* gs://${YOUR_GCS_BUCKET}/data/
Use the TFRecord file in GCS and switch to the models/research directory of the local computer. Next, you will add the pet_label_map.pbtxt file in the GCS bucket. We map the 37 pet species we want to detect to integers one by one so that our model can understand them. Finally, run the following command from the models/research directory:
1 gsutil cp object_detection/data/pet_label_map.pbtxt gs://${YOUR_GCS_BUCKET}/data/pet_label_map.pbtxt
At this time, there are 21 files in the data subdirectory of the GCS bucket: 20 of which are fragmented TFRecord files for training and testing, and a label mapping file.
Use SSD MobileNet checkpoints for transfer learning
In order to be able to recognize pet breeds, we need to use a lot of pictures and spend hours or days training the model from scratch. To speed up this speed, we can use transfer learning to perform similar tasks with model weights trained on large amounts of data, and then train the model on our own data to fine-tune the layers of the pre-trained model.
In order to recognize various objects in an image, we need to train a large number of models. We can use the checkpoints in these training models and then apply them to our custom object detection tasks. This approach is feasible because for machines, there is not much difference between recognizing pixels in images that contain basic objects (such as tables, chairs, or cats) and recognizing pixels in images that contain specific pet breeds.
For this example, we use SSD in combination with MobileNet, which is an object detection model optimized for mobile devices. First, download and extract the latest MobileNet checkpoints that have been pre-trained on the COCO dataset. To see a list of all models supported by the Object Detection API, please check model zoo.
Note: The latest MobileNet checkpoint link
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
Once the checkpoint is successfully decompressed, copy the 3 files to the GCS bucket. Run the following command to download the checkpoint and copy it to the bucket:
1 cd /tmp
2 curl -O http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
3 tar xzf ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
4
5gsutil cp /tmp/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03/model.ckpt.* gs://${YOUR_GCS_BUCKET}/data/
When we train the model, we will use these checkpoints as the starting point for training. You should now have 24 files in your GCS bucket. We are now ready to start the training task, but we need a way to tell ML Engine where our data and model checkpoints are. We will do this with a configuration file, which we will set up in the next step. Our configuration file provides our model with hyperparameters, file path of training data, test data and initial model checkpoint.
Use Cloud TPU to train a quantitative model on Cloud ML Engine
Machine learning models have two different computational components: training and inference. In this example, we use Cloud TPU to accelerate training. We set up Cloud TPU in the configuration file.
When training on Cloud TPU, you can use larger batch sizes because they can handle large datasets more easily (when experimenting with batch sizes on your own dataset, make sure to use multiples of 8 because the data needs to be uniform Assigned to Cloud TPU). Using a larger batch size on our model can reduce the number of training steps (in this example we use 2000).
The focus loss function for this training task is also applicable to Cloud TPU. The definition of the loss function in the configuration file is as follows:
1 loss {
2 classification_loss {
3 weighted_sigmoid_focal {
4 alpha: 0.75,
5 gamma: 2.0
6}
7}
The loss function is used to calculate the loss of each example in the data set, and then recalculate it to assign more relative weight to misclassified examples. Compared with mining operations used in other training tasks, this logic is more suitable for Cloud TPU. You can read more about the loss function in Lin et al. (2017).
The process of initializing pre-trained model checkpoints and then adding our own training data is called transfer learning. The following lines in the configuration tell our model that we will start transfer learning from pre-trained checkpoints.
1 fine_tune_checkpoint: "gs://your-bucket/data/model.ckpt"
2 fine_tune_checkpoint_type: "detection"
We also need to consider how our model will be used after training. Suppose our pet detector becomes a global hit, loved by the majority of animal lovers, and can be seen everywhere in pet stores. We need to handle these inference requests in a scalable, low-latency way. The output of the machine learning model is a binary file that contains the training weights of our model. These files are usually very large, but because we need to deploy this model directly on mobile devices, we need this binary file as small as possible.
This is where the model quantification comes in. Using quantization techniques, we can compress the weights in the model into 8-bit fixed-point representations. The following lines in the configuration file will generate a quantitative model:
1 graph_rewriter {
2 quantization {
3 delay: 1800
4 activation_bits: 8
5 weight_bits: 8
6}
7}
Usually after quantization, the model will perform omni-directional accuracy training in a certain number of steps before switching to quantization training. The delay parameter in the configuration file tells ML Engine to start quantizing weights and activate after 1800 training steps.
In order to tell the ML Engine training and test files and the location of the model checkpoint, you need to update a few lines in the configuration file we created for you to point to your bucket. From the research directory, find the file object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config. Update all PATH_TO_BE_CONFIGURED strings to the absolute path of the data directory in the GCS bucket.
For example, the train_input_reader configuration section will look like this (make sure YOUR_GCS_BUCKET is the name of your bucket):
1 train_input_reader: {
2 tf_record_input_reader {
3 input_path: "gs://YOUR_GCS_BUCKET/data/pet_faces_train*"
4}
5 label_map_path: "gs://YOUR_GCS_BUCKET/data/pet_label_map.pbtxt"
6}
Then copy this quantitative configuration file to your GCS bucket:
1 gsutil cp object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config gs://${YOUR_GCS_BUCKET}/data/pipeline.config
Before we start the training of Cloud ML Engine, we need to package Object Detection API, pycocotools and TF Slim. We can do this with the following command (run this command from the research/ directory and note that the brackets are part of the command):
1 bash
2 object_detection/dataset_tools/create_pycocotools_package.sh /tmp/pycocotools
python setup.py sdist
3 (cd slim && python setup.py sdist)
At this point, we are ready to start training our model! To start training, run the following gcloud command:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_`date +%s` \
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train \
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz \
4 --module-name object_detection.model_tpu_main \
5 --runtime-version 1.8 \
6 --scale-tier BASIC_TPU \
7 --region us-central1 \
8 -- \
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train \
10 --tpu_zone us-central1 \
11 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
Please note that if you receive an error message stating that no Cloud TPU is available, we recommend that you try again in another region (Cloud TPU is currently available for us-central1-b, us-central1-c, europe-west4-a , asia-east1-c).
After starting the training job, run the following command to start the evaluation:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_eval_validation_`date +%s` \
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train \
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz \
4 --module-name object_detection.model_main \
5 --runtime-version 1.8 \
6 --scale-tier BASIC_GPU \
7 --region us-central1 \
8 -- \
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train \
10 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config \
11 --checkpoint_dir=gs://${YOUR_GCS_BUCKET}/train
Both training and evaluation should be completed in approximately 30 minutes. At runtime, you can use TensorBoard to check the accuracy of the model. To start TensorBoard, run the following command:
1 tensorboard --logdir=gs://${YOUR_GCS_BUCKET}/train
Please note that you may need to run gcloud auth application-default login first.
Enter localhost:6006 in the browser address bar to view your TensorBoard output. Here, you will see some commonly used ML indicators for analyzing the accuracy of the model. Please note that these graphs only draw 2 points, because our model is trained quickly in a few steps. The first point here represents the early stage of the training process, and the last point shows the index of the last step.
First, let's take a look at the graph of average precision of 0.5 IOU (mAP @ .50IOU):
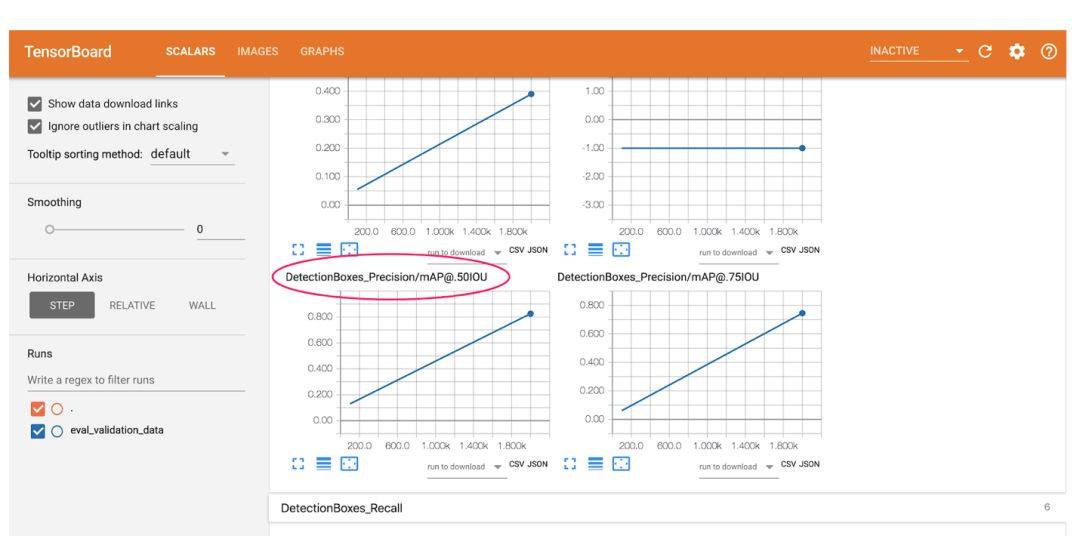
The average accuracy measures the percentage of correctness predictions for all 37 labels by the model. IoU is specific to the object detection model and stands for Intersection-over-Union. We use a percentage to indicate the degree of overlap between the bounding box generated by the measurement model and the ground truth bounding box. This chart shows the percentage of correct bounding boxes and labels returned by the measurement model. In this case, “correct†means that it overlaps with the corresponding ground truth bounding box by 50% or more. After training, our model achieved an average accuracy of 82%.
Next, look at the Images tab in TensorBoard:
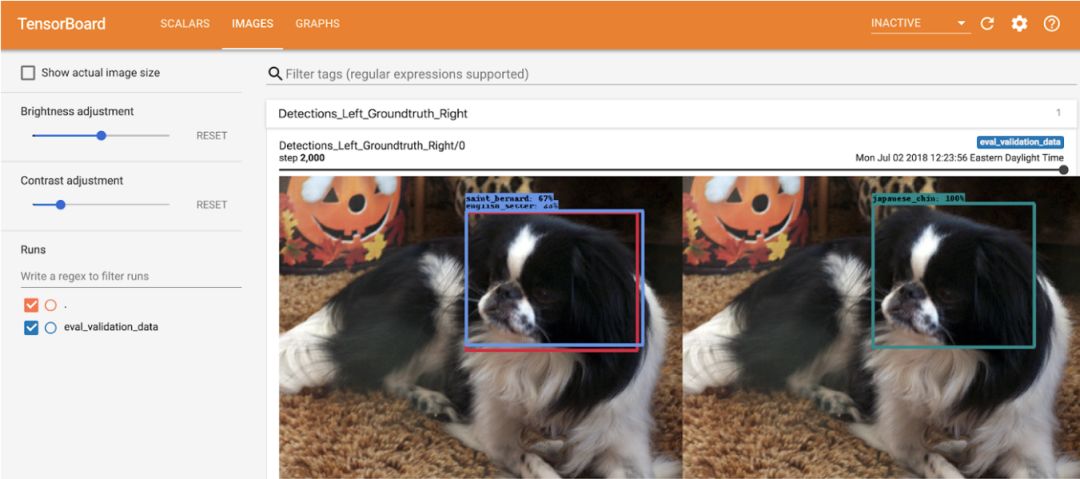
In the left image, we see the model's prediction for this image, and on the right we see the correct ground truth box. The bounding box is very accurate. In this case, the label prediction of our model is incorrect. No ML model is perfect.
Run on mobile devices with TensorFlow Lite
At this point, you will have a well-trained pet detector, you can use this Colab notebook to test the image in the browser with zero settings.
Note: this Colab notebook link
https://colab.research.google.com/github/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
Running this model in real time on a mobile phone requires some extra work --- in this section, I will show you how to use TensorFlow Lite to obtain a smaller model and allow you to take full advantage of optimized operations for mobile devices. TensorFlow Lite is TensorFlow's lightweight solution for mobile and embedded devices. It can perform machine learning inference in a mobile device with low latency and small binary files. TensorFlow Lite uses many techniques, such as quantizing kernels.
As mentioned above, for this section, you need to use the provided Dockerfile, or build TensorFlow from source code (supports GCP) and install the bazel build tool. Please note that if you just want to complete the second part of this tutorial without training the model, we have made a pre-trained model for you.
To make these commands easier to run, let's set some environment variables:
1 export CONFIG_FILE=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
2 export CHECKPOINT_PATH=gs://${YOUR_GCS_BUCKET}/train/model.ckpt-2000
3 export OUTPUT_DIR=/tmp/tflite
We first obtain a TensorFlow frozen graph that contains compatible operations that we can use with TensorFlow Lite. First, you need to install these python libraries. Then, in order to get the frozen graph, run the script export_tflite_ssd_graph.py in the models/research directory:
1 python object_detection/export_tflite_ssd_graph.py \
2 --pipeline_config_path=$CONFIG_FILE \
3 --trained_checkpoint_prefix=$CHECKPOINT_PATH \
4 --output_directory=$OUTPUT_DIR \
5 --add_postprocessing_op=true
In the /tmp/tflite directory, you can see two files:
tflite_graph.pb and tflite_graph.pbtxt (sample frozen graphs are here). Please note that the add_postprocessing flag enables the model to take advantage of custom optimized subsequent detection processing operations, which can be considered as a replacement for tf.image.non_max_suppression. Be sure not to confuse export_tflite_ssd_graph with export_inference_graph. Both of these scripts output the frozen graph: export_tflite_ssd_graph will output the frozen graph that we can directly input to TensorFlow Lite, and it is the graph we will use.
Next, we will use TensorFlow Lite to optimize the model by optimizing the converter. We will use the following command to convert the generated frozen graph (tflite_graph.pb) to the TensorFlow Lite Flatbuffer format (detect.tflite).
1 bazel run -c opt tensorflow/contrib/lite/toco:toco - \
2 --input_file=$OUTPUT_DIR/tflite_graph.pb \
3 --output_file=$OUTPUT_DIR/detect.tflite \
4 --input_shapes=1,300,300,3 \
5 --input_arrays=normalized_input_image_tensor \
6 --output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3' \
7 --inference_type=QUANTIZED_UINT8 \
8 --mean_values=128 \
9 --std_values=128 \
10 --change_concat_input_ranges=false \
11 --allow_custom_ops
After adjusting each camera image frame to 300x300 pixels, this command uses the input tensor normalized_input_image_tensor.
The output of the quantization model is named'TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2', and'TFLite_Detection_PostProcess:3', respectively representing four arrays: detection_boxes, detection_classes, detection_scores and num_detections. If it runs successfully, you should now see a file named detect.tflite in the /tmp/tflite directory. This file contains graphics and all model parameters, can be run by the TensorFlow Lite interpreter on Android devices, and the file is less than 4 Mb.
Run the model on an Android device
To run our final model on the device, we need to use the provided Dockerfile, or install the Android NDK and SDK. The currently recommended Android NDK version is 14b, which can be found on the NDK Archives page. Please note that the current version of Bazel is not compatible with NDK 15 and later. The Android SDK and build tools can be downloaded separately or used as part of Android Studio. In order to compile TensorFlow Lite Android Demo, the build tool requires API >= 23 (but it will run on devices with API >= 21). Other details can be found on the TensorFlow Lite Android App page.
Before trying to obtain the newly trained pet model, first run the demo application with the default model, which is trained on the COCO dataset. To compile the demo application, run this bazel command from the tensorflow directory:
1 bazel build -c++ opt --config=android_arm{,64} --cxxopt='--std=c++11' \
2 //tensorflow/contrib/lite/examples/android:tflite_demo
The above apk is compiled for 64-bit architecture. In order to support the 32-bit architecture, you can modify the compilation parameter to - config=android_arm. Now you can install the demo on Android phones that support debugging mode through the Android Debug Bridge (adb):
1 adb install bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
Try to launch the app (called TFLDetect) and point the camera at people, furniture, cars, pets, etc. You will see a labelled frame around the detected object. This application uses the COCO data set for training.
Once the universal detector is successfully run, it will be very simple to replace it with your custom pet detector. All we need to do is point the application to our new detect.tflite file and give it the name of the new label. Specifically, we will use the following command to copy the TensorFlow Lite Flatbuffer resource to the app assets directory:
1 cp /tmp/tflite/detect.tflite \
2 tensorflow/contrib/lite/examples/android/app/src/main/assets
We will now edit the BUILD file to point to the new model. First, open the BUILD file in the directory tensorflow/contrib/lite/examples/android/. Then find the assets section and replace the line "@tflite_mobilenet_ssd_quant//:detect.tflite" (pointing to the COCO pre-trained model by default) with your TFLite pet model path (" //tensorflow/contrib/lite/examples/android /app/src/main/assets:detect.tflite"). Finally, change the last line of the assets section to use the new label mapping. As follows:
1 assets = [
2 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:labels_mobilenet_quant_v1_224.txt",
3 "@tflite_mobilenet//:mobilenet_quant_v1_224.tflite",
4 "@tflite_conv_actions_frozen//:conv_actions_frozen.tflite",
5 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:conv_actions_labels.txt",
6 "@tflite_mobilenet_ssd//:mobilenet_ssd.tflite",
7 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:detect.tflite",
8 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:box_priors.txt",
9 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:pets_labels_list.txt",
10 ],
We also need to tell our application to use the new label mapping. To do this, open the tensorflow/contrib/lite/examples/android/app/src/main/java/org/tensorflow/demo/DetectorActivity.java file in a text editor and find the variable TF_OD_API_LABELS_FILE. Update this variable to: "file:///android_asset/pets_labels_list.txt" to point to your pet label mapping file. Please note that we have created pets_labels_list.txt file for convenience.
DetectorActivity.java is modified as follows:
1 // Configuration values ​​for the prepackaged SSD model.
2 private static final int TF_OD_API_INPUT_SIZE = 300;
private static final boolean TF_OD_API_IS_QUANTIZED = true;
3 private static final String TF_OD_API_MODEL_FILE = "detect.tflite";
4 private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/pets_labels_list.txt";
Once we have copied the TensorFlow Lite files and edited the BUILD and DetectorActivity.java files, we can recompile and install the application using the following command:
1 bazel build -c opt --config=android_arm{,64} --cxxopt='--std=c++11' \
2 //tensorflow/contrib/lite/examples/android:tflite_demo
3 adb install -r bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
Now is the time to witness the miracle: find the cats and dogs closest to you and try to detect them.
5V Dc Adapter,Plug Interchangeable Ac Dc Adapter,5V 1A Power Adapter,Dc 5V 1A Adapter
ShenZhen Yinghuiyuan Electronics Co.,Ltd , https://www.yhypoweradapter.com